یادگیری تقویتی (Reinforcement Learning، بهاختصار RL) شاخهای از هوش مصنوعی است که در آن سیستم یا عامل، با آزمون و خطا و دریافت بازخوردهای مثبت یا منفی، بهینهترین استراتژیهای تصمیمگیری را میآموزد. در این مطلب از سری مطالب آموزشی وبلاگ پارس وی دی اس به یادگیری تقویتی (RL) چیست و چه جایگاهی در هوش مصنوعی دارد میپردازیم.
در این روش، عامل در محیطی قرار میگیرد و بر اساس عملکرد خود، پاداش یا تنبیه دریافت میکند، و هدف او پیدا کردن سیاستی است که بیشترین پاداش را در طول زمان جمعآوری کند.
یادگیری تقویتی در کنار دیگر شاخههای هوش مصنوعی مانند یادگیری ماشین و یادگیری عمیق، جایگاهی ویژه دارد، زیرا قادر است مسائل پیچیده و دنیای واقعی مانند بازیهای رایانهای، رباتیک، خودرانها و سیستمهای توصیهگر را با موفقیت حل کند. این حوزه از هوش مصنوعی، با تمرکز بر توسعه الگوریتمهایی که قابلیت یادگیری از تعامل با محیط را دارند، نقش مهمی در پیشرفت فناوریهای هوشمند و خودکار ایفا میکند.

یادگیری تقویتی (Reinforcement Learning – RL) چیست؟
یادگیری تقویتی (Reinforcement Learning – RL) یکی از شاخههای مهم و پرکاربرد در حوزه یادگیری ماشین است که بر اساس اصول رفتار و یادگیری انسانی توسعه یافته است. در این رویکرد، یک عامل (agent) در محیطی مشخص قرار میگیرد و با انجام اقداماتی، سعی در به حداکثر رساندن سیگنال پاداش (reward) دارد. این سیگنال نشان میدهد که عملکرد عامل تا چه حد موفق بوده است و به او کمک میکند تا استراتژیهای بهتری را بیاموزد.
نحوه عملکرد یادگیری تقویتی:
در فرآیند RL، عامل با آزمون و خطا، بهترین استراتژیها یا سیاستها را برای اقدام در محیط پیدا میکند. این فرآیند شامل دو عملکرد حیاتی است:
- استفاده (Exploitation): بهرهبرداری از تجربیات قبلی برای انجام بهترین اقدام ممکن.
- کاشف (Exploration): بررسی اقداماتی جدید و ناشناخته برای درک بهتر محیط و یافتن راهکارهای بهتر.
این تعادل بین کاوش و بهرهبرداری، کلید موفقیت در یادگیری تقویتی است و الگوریتمهایی مانند Q-Learning و Deep Q-Networks (DQN) از آن بهره میبرند. Q-Learning، یکی از مشهورترین الگوریتمهای RL، توانایی یادگیری سیاست بهینه در محیطهای گسسته و ثابت را دارد. در حالی که DQN، با استفاده از شبکههای عصبی عمیق، قابلیت کار در محیطهای پیچیدهتر و دینامیکتر را داراست.
کاربردهای RL:
یادگیری تقویتی در حوزههای متعددی کاربرد دارد، از جمله:
- بازیهای رایانهای و شبیهسازیهای استراتژیک مانند بازی شطرنج و گو.
- رباتیک، برای آموزش رباتها در انجام وظایف پیچیده و تعامل با محیط.
- مدیریت منابع و بهینهسازی عملیات در صنایع مختلف.
- سیستمهای پیشنهاد دهنده در فناوریهای مختلف، مانند سیستمهای توصیه در نتفلیکس و آمازون.
- هوش مصنوعی در خودروهای خودران و سیستمهای کنترل هوشمند.
روشها و الگوریتمها در RL:
علاوه بر Q-Learning و DQN، روشهایی مانند سیاست گرادیان (Policy Gradient) و Actor-Critic نیز در RL استفاده میشوند. این الگوریتمها بهبود کارایی، پایداری و قابلیت تعمیم در محیطهای واقعی و پیچیده را هدف دارند.
تفاوت هوش مصنوعی و یادگیری تقویتی:
هوش مصنوعی (Artificial Intelligence – AI) شاخه وسیعی است که شامل تمامی فناوریهایی است که قابلیت انجام وظایف انسانی را دارند، از جمله یادگیری ماشین، پردازش زبان طبیعی، بینایی ماشین و رباتیک. در حالی که یادگیری تقویتی، یکی از زیرشاخههای یادگیری ماشین است که بر آموزش عاملها برای تصمیمگیری بر اساس بازخورد محیط تمرکز دارد.
بازار کار و آینده RL:
بازار کار در حوزه RL در حال رشد است و شرکتهای فناوری، خودروسازان، و مؤسسات تحقیقاتی به شدت در حال سرمایهگذاری بر روی این فناوری هستند. فرصتهای شغلی در زمینه توسعه الگوریتمهای RL، پیادهسازی در سیستمهای صنعتی و بازیهای رایانهای، و تحقیقات پیشرفته در حال افزایش است. همچنین، پیشرفتهای اخیر در هوش مصنوعی، مانند یادگیری عمیق، موجب گسترش دامنه کاربردهای RL شده است و انتظار میرود در آینده نقش مهمتری در زندگی روزمره و صنایع ایفا کند.

جایگاه یادگیری تقویتی (RL) در حوزه هوش مصنوعی
یادگیری تقویتی (Reinforcement Learning – RL) یکی از شاخههای بنیادی و در حال توسعه در حوزه هوش مصنوعی است که به مطالعه و طراحی سیستمهایی میپردازد که میتوانند از طریق تعامل با محیط، به صورت مستقل و بدون نیاز به دستورالعملهای صریح، رفتارهای بهینه را یاد بگیرند. در این رویکرد، عامل (Agent) با دریافت بازخوردهای مثبت یا منفی از محیط، به تدریج استراتژیهای تصمیمگیری خود را بهبود میبخشد تا بتواند در بلندمدت بیشترین پاداش ممکن را کسب کند.
در فرآیند RL، عامل اقداماتی را در هر وضعیت انجام میدهد و به ازای هر اقدام، بازخوردی دریافت میکند که به آن سیگنال پاداش گفته میشود. هدف اصلی، پیدا کردن سیاستی است که مجموع پاداشهای دریافتی در طول زمان را حداکثر کند. این فرآیند یادگیری، در بسیاری از حوزهها کاربرد دارد، از جمله رباتیک (برای آموزش رباتها به انجام وظایف پیچیده)، بازیهای رایانهای (مانند بازیهای استراتژیک و شطرنج)، مدیریت منابع و ترافیک، بهینهسازی سیستمهای حملونقل، سیستمهای توصیهگر در تجارت الکترونیک، سیستمهای مالی و بهداشت و درمان.
یکی از نقاط قوت RL، توانایی آن در یادگیری از تعامل مستقیم با محیطهای پیچیده و نامحدود است، که این امر مهمترین تفاوت آن با روشهای یادگیری نظارتشده است. همچنین، توسعه الگوریتمهای پیشرفته مانند Q-Learning، Policy Gradient، Deep Q-Networks (DQN) و Actor-Critic، موجب افزایش کارایی و قابلیتهای سیستمهای RL شده است. با پیشرفت فناوریهای محاسباتی، به کارگیری شبکههای عصبی عمیق در RL (که به آن Deep Reinforcement Learning یا Deep RL گفته میشود) موجب افزایش قدرت و انعطافپذیری عاملها در یادگیری وظایف پیچیده، درک بهتر محیطهای بزرگ و چندبعدی، و بهبود عملکرد در مسائل واقعی شده است.
در حال حاضر، بسیاری از شرکتها و مؤسسات تحقیقاتی در حال توسعه و بهبود الگوریتمهای RL هستند تا چالشهایی مانند پایداری آموزش، انتقال دانش بین وظایف، و مقیاسپذیری در محیطهای بزرگ و دینامیک را حل کنند. یکی از حوزههای فعال در این زمینه، ترکیب RL با فناوریهای دیگر مانند یادگیری عمیق، یادگیری انتقالی، و یادگیری چندوظیفهای است که به توسعه سیستمهای هوشمندتر و قابل اعتمادتر کمک میکند.

یادگیری تقویتی به عنوان یکی از اصولیترین و پرکاربردترین روشهای هوش مصنوعی، با قابلیت تعامل هوشمند و تطابق با محیطهای متنوع، نقش حیاتی در آینده فناوریهای هوشمند ایفا میکند. تحقیقات جاری و آیندهنگر در این حوزه، تمرکز بر بهبود پایداری، سرعت، و قابلیت تعمیم الگوریتمها است تا بتوانند در محیطهای واقعی و پیچیده، کاربردیتر و مؤثرتر باشند.
نحوه عملکرد یادگیری تقویتی (Reinforcement Learning – RL)
یادگیری تقویتی یکی از شاخههای مهم و پویای یادگیری ماشینی است که بر اساس تعامل مداوم بین عامل (Agent) و محیط (Environment) کار میکند. در این رویکرد، عامل با انجام اقدامات در محیط، تجربه کسب میکند و بر اساس این تجربیات، بهترین رفتارها و تصمیمها را برای رسیدن به هدف تعیین شده یاد میگیرد. این روش به ویژه در مسائل پیچیده و دنیای واقعی کاربرد فراوان دارد، مانند رباتیک، بازیهای ویدیویی، کنترل سیستمهای صنعتی و خودرانها.
اجزاء اصلی یادگیری تقویتی:
- عامل (Agent): موجود یا سیستم هوشمندی است که در حال یادگیری و تصمیمگیری است. عامل اقدامات خود را بر اساس سیاست فعلی انجام میدهد و هدف نهاییاش به حداکثر رساندن جمع کل پاداش دریافتی است.
- محیط (Environment): دنیای واقعی یا مجازی که عامل در آن فعالیت میکند. محیط وضعیتهای مختلفی دارد و بر اساس اقدامات عامل پاسخ میدهد، پاداش میدهد یا تنبیه میکند و وضعیت جدیدی را ایجاد میکند.
- پاداش (Reward): سیگنالی است که پس از انجام هر اقدام توسط عامل، از محیط دریافت میشود. هدف عامل، جمعآوری حداکثر مقدار پاداش در طول زمان است که نشاندهنده موفقیت در رسیدن به هدف است.
- سیاست (Policy): راهنمایی است که تعیین میکند در هر وضعیت، عامل چه اقدامی انجام دهد. سیاست میتواند یک تابع ریاضی، مجموعه قوانین یا شبکه عصبی باشد که تصمیمات عامل را هدایت میکند.
- تابع ارزش (Value Function): معیاری است که میزان سودمندی هر وضعیت یا اقدام را بر اساس انتظار دریافت پاداش در آینده ارزیابی میکند. این تابع به عامل کمک میکند تا تصمیمگیریهای هوشمندانهتری داشته باشد.
مراحل عملکرد یادگیری تقویتی:
تعریف مسئله: در ابتدا باید مسئله مورد نظر با دقت مشخص شود، شامل تعیین وضعیتهای ممکن، اقدامات مجاز، نحوه دریافت پاداش و هدف نهایی که معمولاً حداکثر کردن مجموع پاداش است.
انتخاب محیط مناسب: بر اساس نوع مسئله، محیطی طراحی یا انتخاب میشود که بتواند تعامل مؤثر بین عامل و محیط برقرار کند. این محیط میتواند یک شبیهساز، محیط واقعی یا محیط مجازی باشد.
انتخاب الگوریتم مناسب: بسته به پیچیدگی مسئله و نوع دادهها، الگوریتمهای مختلفی مانند Q-learning، Deep Q-Networks (DQN)، Policy Gradient، Actor-Critic و سایر روشها مورد استفاده قرار میگیرند. هر کدام مزایا و محدودیتهای خاص خود را دارند.
آموزش عامل: در این مرحله، عامل با تعامل با محیط، از طریق اجرای اقدامات و دریافت پاداشها، سیاست خود را بهبود میبخشد. فرآیند آموزش ممکن است نیازمند چندین دوره تکرار (اپیزود) باشد تا عامل به سیاست بهینه برسد.
ارزیابی و بهبود: عملکرد عامل باید به صورت مداوم ارزیابی شود تا مشخص شود که آیا سیاست فعلی به نتایج مطلوب میرسد یا نیاز به اصلاح دارد. این ارزیابیها معمولاً بر اساس معیارهای مختلفی مانند میانگین پاداش در اپیزودهای آزمایشی انجام میشود.
در دهههای اخیر، یادگیری تقویتی شاهد پیشرفتهای قابل توجهی بوده است، بهویژه با ظهور یادگیری عمیق (Deep Learning). ترکیب RL و شبکههای عصبی عمیق منجر به توسعه الگوریتمهایی مانند Deep Q-Networks (DQN) شده است که توانایی حل مسائل پیچیده با فضاهای حالت بزرگ و غیرخطی را دارند. این پیشرفتها موجب شده است کاربردهای یادگیری تقویتی در حوزههایی مانند رانندگی خودران، بازیهای استراتژیک مانند شطرنج و گو، مدیریت انرژی، و سیستمهای توصیهگر گسترش یابد.
کاربردهای یادگیری تقویتی (RL) در حوزه هوش مصنوعی و فناوریهای نوین
یادگیری تقویتی (Reinforcement Learning – RL) یکی از شاخههای پیشرفته و پویا در حوزه هوش مصنوعی است که بر پایه آموزش سیستمها از طریق تعامل با محیط و دریافت پاداش یا تنبیه، به آنها امکان میدهد مهارتها و استراتژیهای خود را به صورت خودکار توسعه دهند. این رویکرد در بسیاری از صنایع و برنامههای کاربردی نقش حیاتی ایفا میکند و توانایی حل مسائل پیچیده، بهبود کارایی و افزایش خودکارسازی را داراست. در ادامه، برخی از مهمترین کاربردهای RL را بررسی میکنیم و نگاهی گستردهتر به نقش آن در فناوریهای امروزی خواهیم داشت.
بازیهای ویدئویی و هوش مصنوعی RL :
در توسعه هوش مصنوعی برای بازیهای ویدئویی، نمونههای برجستهای مانند AlphaGo و Dota 2 را به وجود آورده است. این سیستمها با یادگیری استراتژیهای مبتنی بر تجربه، میتوانند در مقابل انسانها و دیگر رباتهای هوشمند رقابت کنند و راهکارهای برتر را برای پیروزی کشف نمایند. همچنین، RL در بهبود استراتژیهای چندنفره و توسعه بازیهای تعاملی با قابلیت یادگیری خودکار نقش مهمی دارد.
رباتیک و اتوماسیون صنعتی:
در صنعت رباتیک، RL به رباتها امکان میدهد تا به صورت مستقل مهارتهای جدید را بیاموزند، از جمله ناوبری در محیطهای پیچیده، انجام وظایف دقیق و تنظیم خودکار ابزارها. این تکنیک بهبود قابل توجهی در قابلیتهای رباتها، کاهش هزینههای آموزش و افزایش انعطافپذیری در عملیاتهای صنعتی فراهم میآورد. نمونههایی از این کاربرد شامل رباتهای خدماتی، رباتهای جراحی و رباتهای خودران در خطوط تولید میشود.
سیستمهای مدیریت منابع و بهینهسازی:
عملیات RL در بهینهسازی سیستمهای مدیریت منابع، مانند شبکههای توزیع برق، سیستمهای حملونقل و مدیریت موجودی انبارها، نقش حیاتی دارد. با یادگیری مستمر از دادههای محیط، این تکنیکها میتوانند تصمیمات بهینهتری در تخصیص منابع، کاهش هدررفت و افزایش بهرهوری اتخاذ کنند. به عنوان مثال، در شبکههای هوشمند برق، RL برای تنظیم میزان تولید و مصرف، کاهش تلفات و مدیریت بارهای اوج کاربرد دارد.
خودروهای خودران و حملونقل هوشمند:
در زمینه وسایل نقلیه هوشمند، RL به بهبود تصمیمگیری در خودروهای خودران و هواپیماهای بدون سرنشین کمک میکند. این سیستمها با تحلیل محیط، پیشبینی حرکتهای دیگر وسایل و انتخاب بهترین مسیر، امنیت و کارایی سفر را افزایش میدهند. همچنین، RL در کنترل ترافیک و بهبود سیستمهای حملونقل عمومی نقشآفرینی میکند.
بهبود عملکرد سیستمهای مخابراتی و شبکههای ارتباطی:
در صنعت مخابرات، RL برای بهینهسازی تخصیص فرکانس، مدیریت ترافیک شبکه، کاهش تداخل و ارتقاء کیفیت سرویسها به کار میرود. این فناوری میتواند به صورت دینامیک و در زمان واقعی، منابع شبکه را تنظیم کند تا بهترین عملکرد را برای کاربران فراهم آورد.

کاربردهای دیگر و رویکردهای نوین علاوه بر موارد فوق، RL در حوزههایی مانند سلامتی و پزشکی (مانند شخصیسازی درمانها و کنترل ردیابی بیماریها)، مالی و بازارهای سرمایه (برای مدیریت پرتفوی و معاملات الگوریتمی)، آموزش و یادگیری شخصیسازی شده، و سیستمهای هوشمند خانگی و شهرهای هوشمند، در حال گسترش است. همچنین، ترکیب RL با تکنیکهای یادگیری عمیق، منجر به توسعه الگوریتمهای قدرتمند مانند Deep Reinforcement Learning شده است که میتوانند مسائل بسیار پیچیده و بزرگ را حل کنند.
روشهای یادگیری تقویتی (Reinforcement Learning – RL)
یادگیری تقویتی یکی از شاخههای برجسته و پیشرفته در حوزه علوم کامپیوتر و هوش مصنوعی است که به مطالعه روشهایی میپردازد که یک عامل (Agent) میتواند در محیطهای پویا و دینامیک، به صورت بهینه تصمیمگیری کند، آموزش ببیند و عملکرد خود را بهبود بخشد. این حوزه کاربردهای گستردهای در رباتیک، بازیهای رایانهای، سیستمهای خودران، مدیریت منابع و سایر زمینههای تصمیمگیری دارد.
یادگیری تقویتی بر پایه مدلسازی مسائلی است که میتوان آنها را به عنوان فرایندهای تصمیمگیری مارکوف (Markov Decision Processes – MDPs) تعریف کرد، جایی که تصمیمات در هر حالت بر اساس سیاستهایی اتخاذ میشود که منجر به بیشینه کردن پاداش تجمعی در طول زمان است.
روشهای اصلی در یادگیری تقویتی شامل موارد زیر است:
- روشهای مبتنی بر تعامل مستقیم با محیط: در این روشها، عامل به طور مکرر با محیط تعامل دارد، اقداماتی انجام میدهد و پاداشهایی دریافت میکند. هدف، یادگیری سیاست یا تابع ارزش که بهترین تصمیمها را در هر وضعیت مشخص کند.
- روشهای بر پایه تابع ارزش (Value-based methods): این روشها بر تخمین و بهروزرسانی تابع ارزش (مثل Q-function) تمرکز دارند تا بر اساس آن تصمیمگیری صورت گیرد.
- روشهای بر پایه سیاست (Policy-based methods): در این رویکردها، مستقیم به بهینهسازی خود سیاست میپردازند، بدون نیاز به تخمین تابع ارزش.
- ترکیب روشهای Actor-Critic: این دسته، تلفیقی از دو روش فوق است که هم تابع ارزش و هم سیاست را همزمان بهبود میبخشد.
در ادامه، به معرفی مهمترین الگوریتمها و فناوریهای مورد استفاده در یادگیری تقویتی میپردازیم:
الگوریتمهای Q-Learning Q-Learning :
یکی از پایههای اصلی در یادگیری تقویتی است که بر تخمین تابع ارزش عمل (Q-function) تمرکز دارد. در این الگوریتم، عامل با تعامل مکرر با محیط، به صورت تجربی مقادیر Q را بهروزرسانی میکند تا زمانی که به تابع ارزش بهینه برسد. این روش در محیطهای با فضای عمل محدود و مشخص بسیار کاربرد دارد و به دلیل سادگی و اثربخشی، در بسیاری از مسائل مورد استفاده قرار میگیرد.
الگوریتمهای Policy Gradient:
این الگوریتمها به جای تخمین تابع ارزش، بر مستقیم بهینگی سیاست تمرکز دارند. آنها با استفاده از گرادیان سیاست، پارامترهای سیاست را به سمت سیاستهای بهتر بهروزرسانی میکنند. از مزایای این روشها میتوان به توانایی آنها در تعمیم به سیاستهای پیوسته و پیچیده اشاره کرد.
الگوریتمهای Actor-Critic:
این دسته از الگوریتمها، ترکیبی از روشهای فوق هستند؛ یعنی یک شبکه عصبی (Actor) که سیاست را تعیین میکند و یک تابع ارزش (Critic) که ارزیابی عملکرد سیاست فعلی را بر عهده دارد. این رویکرد، تعادل خوبی بین بهرهوری و پایداری در آموزش مدلها ایجاد میکند.
الگوریتمهای Deep Q-Networks (DQN) DQN، یکی از پیشرفتهای مهم در یادگیری تقویتی است که با استفاده از شبکههای عصبی عمیق، تابع Q را تقریب میکند. این فناوری توانسته است محدودیتهای مدلهای قدیمیتر را برطرف کند و در مسائلی با فضای حالت و عمل بزرگ، عملکرد قابل توجهی نشان دهد. DQN در بازیهای رایانهای مانند Atari موفقیتهای چشمگیری کسب کرده است.
الگوریتمهای اصلاح شده مانند Double DQN و Dueling DQN این الگوریتمها، نسخههای بهبود یافتهای از DQN هستند که مشکلات رایج آن مانند overestimation (تخمین بیش از حد ارزشها) را برطرف میکنند. Double DQN با جدا کردن فرآیند انتخاب و ارزیابی اقدام، تخمینهای دقیقتری ارائه میدهد و Dueling DQN با ساختار خاص خود، ارزش حالت و اقدام را به صورت جداگانه مدلسازی میکند، که منجر به بهبود کارایی میشود.
تفاوت هوش مصنوعی با یادگیری تقویتی: مروری جامع و جامعتر
هوش مصنوعی (Artificial Intelligence) و یادگیری تقویتی (Reinforcement Learning) دو مفهوم بنیادی و مهم در حوزه علوم کامپیوتر، یادگیری ماشین و هوش مصنوعی هستند که هر کدام نقش و کاربرد خاص خود را دارند. این دو مفهوم اغلب در محافل علمی و صنعتی با یکدیگر اشتباه گرفته میشوند، اما در واقع تفاوتهای اساسی و مهمی دارند. در ادامه، به بررسی جامع این تفاوتها پرداخته و اطلاعات بیشتری در این زمینه ارائه میدهیم.
مفهوم و کاربرد:
هوش مصنوعی (AI): هوش مصنوعی شامل مجموعهای از تکنیکها، الگوریتمها و سیستمهایی است که به ماشینها و کامپیوترها امکان میدهد وظایف هوشمندانهای مانند تشخیص تصویر، ترجمه زبان، پردازش زبان طبیعی، تصمیمگیری، برنامهنویسی خودکار، و پیشنهاد محتوا را انجام دهند. هدف اصلی هوش مصنوعی توسعه سیستمهایی است که بتوانند به صورت مستقل و در موارد مختلف، رفتارهای انسانی یا حتی برتر از آنها را شبیهسازی کنند. این فناوری در حوزههایی مانند رباتیک، پزشکی، خودرانها، خدمات مشتریان، و تحلیل دادههای بزرگ کاربردهای فراوانی دارد.
یادگیری تقویتی (Reinforcement Learning): یادگیری تقویتی یکی از شاخههای یادگیری ماشین است که بر اساس تعامل مستقیم عامل (Agent) با محیط اطراف خود شکل میگیرد. در این روش، عامل با انجام اقداماتی در محیط، پاداش یا مجازات دریافت میکند، و هدف نهایی او، به حداکثر رساندن مجموع پاداشهایی است که در طول زمان دریافت میکند. این نوع یادگیری برای توسعه سیستمهایی مناسب است که در آنها باید استراتژیهای بهینه برای انجام وظایف پیچیده و دینامیکهای محیطی پیدا شود، مانند بازیهای استراتژیک، رباتیک، و سیستمهای خودکار مبتنی بر تجربه.
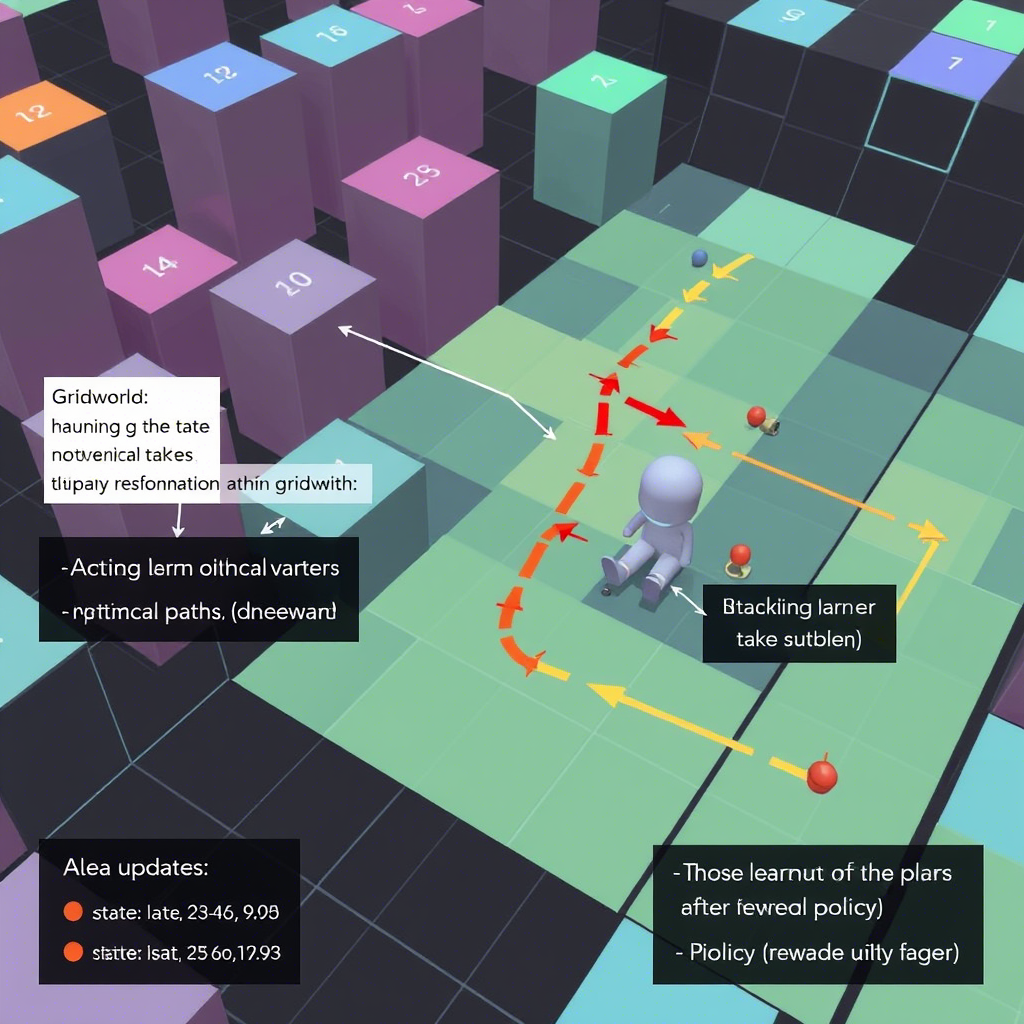
روشها و الگوریتمها:
هوش مصنوعی: در این حوزه، از مجموعهای گستردهای از تکنیکها و الگوریتمها استفاده میشود، از جمله شبکههای عصبی عمیق (Deep Neural Networks)، الگوریتمهای یادگیری ماشین مانند ماشینهای بردار پشتیبان (SVM)، درختهای تصمیمگیری، الگوریتمهای مبتنی بر منطق فازی، و سیستمهای استنتاج. این الگوریتمها بر اساس دادههای آموزشدیده و مدلسازیهای پیچیده، وظایف خاصی را انجام میدهند و معمولاً نیازمند مجموعهای از دادههای بزرگ و متنوع هستند.
یادگیری تقویتی: در این روش، الگوریتمهایی مانند Q-learning، SARSA، و الگوریتمهای مبتنی بر سیاست (Policy Gradient) برای یادگیری استراتژیهای بهینه استفاده میشوند. این الگوریتمها بر اساس قوانین پاداش و مجازات، رفتار عامل را تنظیم و بهبود میبخشند، و در مسائل زمانبر و پیچیده که نیازمند تصمیمگیریهای متوالی هستند، بسیار مؤثر عمل میکنند. یادگیری تقویتی در مواردی مانند بازیهای استراتژیک (مثلاً شطرنج، Go)، کنترل ربات، و سیستمهای توصیهگر پیچیده کاربرد دارد.
هدف و انگیزه:
هوش مصنوعی: هدف اصلی هوش مصنوعی توسعه سیستمهایی است که بتوانند وظایف انسانی یا حتی بهتر از آنها را انجام دهند، بدون نیاز به آموزش مستقیم در هر مورد، بلکه با استفاده از مدلسازیهای پیشرفته و تحلیل دادهها. این سیستمها باید قادر باشند تعمیم دهند، خطاهای احتمالی را کاهش دهند و در محیطهای مختلف عمل کنند.
یادگیری تقویتی: هدف اصلی در یادگیری تقویتی، آموزش عامل به گونهای است که بتواند استراتژیهای تصمیمگیری بهینه را پیدا کند، بهگونهای که مجموع پاداشها در طول زمان بیشینه شود. این نوع یادگیری برای مسائل پویا و دینامیک که در آنها اطلاعات کامل در ابتدا در اختیار نیست و عامل باید با تجربه بیاموزد، بسیار حیاتی است.
نکات تکمیلی:
-
- هوش مصنوعی شامل روشهایی است که ممکن است نیاز به آموزشهای گسترده و دادههای متنوع داشته باشند، اما در عین حال قابلیت تعمیم و چندمنظوره بودن را دارند.
- یادگیری تقویتی در کنار مزایای خود، نیازمند تعامل مستمر و زمانبر است، اما میتواند در مسائل عدم قطعیت و محیطهای دینامیک بسیار مؤثر باشد.
بازار کار یادگیری تقویتی (RL)
یادگیری تقویتی (Reinforcement Learning – RL) به عنوان یکی از شاخههای پیشرفته و نوآورانه هوش مصنوعی، در سالهای اخیر توجه بسیاری را به خود جلب کرده است. این حوزه به دلیل قابلیتها و کاربردهای گستردهاش در حل مسائل پیچیده و تصمیمگیریهای هوشمندانه، تأثیر عمیقی بر بازار کار گذاشته است. RL به توسعهدهندگان و محققان این امکان را میدهد تا عاملهای هوشمندی طراحی کنند که بتوانند با محیطهای متنوع تعامل داشته و بر اساس تجربیات گذشته، رفتارهای بهینه را بیاموزند.
کاربردهای RL در صنایع مختلف:
این فناوری در حوزههای متعددی کاربرد دارد، از جمله:
- بازیهای رایانهای و طراحی استراتژیهای خودیادگیر، که منجر به پیشرفتهای قابل توجه در هوش مصنوعی بازیها شده است.
- رباتیک، برای توسعه رباتهایی که توانایی انجام وظایف پیچیده و تطبیق با محیطهای متغیر را دارند.
- مدیریت منابع، در بهینهسازی مصرف انرژی، ترافیک، و توزیع منابع در شبکههای بزرگ.
- برنامهریزی زمان و عملیات، برای خودکارسازی فرآیندهای تولید و خدمات.
- مالی و سرمایهگذاری، جایی که RL در طراحی استراتژیهای معاملاتی و مدیریت ریسک به کار میرود.
- سلامت و پزشکی، برای بهبود راهبردهای درمان و تشخیص بیماریها.
مزایای بازار کار یادگیری تقویتی (RL) و فرصتهای شغلی
یکی از اصلیترین مزایای RL، قابلیت تطبیق و یادگیری مستمر از تجربیات است. این توانایی در محیطهای ناپایدار و غیرقطعی، به ویژه در بازارهای مالی، تجارت، و فناوریهای نوین، بسیار ارزشمند است. متخصصان این حوزه میتوانند در توسعه الگوریتمهای پیشرفته، بهبود فرآیندهای تصمیمگیری، و طراحی سیستمهای خودران نقشآفرین باشند.
افزایش نیاز به مهارتهای RL در بازار کار، منجر به رشد فرصتهای شغلی در شرکتهای فناوری، استارتاپها، مؤسسات مالی، و مراکز تحقیق و توسعه شده است. مهندسان نرمافزار، دانشمندان داده، محققان هوش مصنوعی، و تحلیلگران کسبوکار که توانایی کار با الگوریتمهای RL دارند، در بازارهای رقابتی امروزی از مزیت برخوردارند.
آینده بازار کار و چالشها:
با توجه به پیشرفتهای سریع در حوزه هوش مصنوعی و یادگیری ماشین، انتظار میرود که نیاز به متخصصان RL در دهه آینده افزایش یابد. شرکتها به دنبال راهکارهای هوشمند برای بهبود کارایی، کاهش هزینهها، و ایجاد نوآوریهای مستمر هستند. از سوی دیگر، این حوزه با چالشهایی همچون نیاز به دادههای بزرگ، پیچیدگیهای محاسباتی، و مسائل اخلاقی در تصمیمگیریهای خودران مواجه است که نیازمند تخصص و دانش عمیق است.
در نتیجه، تسلط بر یادگیری تقویتی نه تنها فرصتهایی برای کسب درآمد و توسعه حرفهای فراهم میآورد، بلکه فرد را در مسیر پیشرفت در حوزههای فناوری، مالی، و تحقیقات علمی قرار میدهد. این مهارت، به عنوان یکی از ارکان اصلی آینده هوش مصنوعی، میتواند به عنوان یک مزیت رقابتی قوی در بازار کار کشورهای توسعهیافته و در حال توسعه محسوب شود.
آموزش مدلهای یادگیری عمیق با هوش مصنوعی: راهنمای جامع و قدمبهقدم
در این مقاله، به بررسی مفاهیم پایهای و عمیق در حوزه یادگیری عمیق (Deep Learning)، انواع مدلهای موجود، فرآیند آموزش آنها با بهرهگیری از هوش مصنوعی، و آموزش گامبهگام با زبان برنامهنویسی پایتون میپردازیم. همچنین تفاوتهای کلیدی بین یادگیری عمیق و یادگیری ماشین (Machine Learning) نیز مورد بررسی قرار میگیرد.
مفهوم یادگیری عمیق:
هوش مصنوعی (Artificial Intelligence – AI) شاخهای از علم کامپیوتر است که هدف آن ساخت سیستمهایی است که بتوانند وظایف انسانی مانند تشخیص تصویر، ترجمه زبان، و تصمیمگیری را انجام دهند. یکی از زیرشاخههای مهم این حوزه، یادگیری ماشین (Machine Learning) است که بر پایه آموزش ماشینها با دادهها و الگوریتمهای آماری استوار است.
یادگیری عمیق (Deep Learning) که زیرمجموعهای از یادگیری ماشین محسوب میشود، بر توسعه شبکههای عصبی مصنوعی عمیق تمرکز دارد. این فناوری بدون نیاز به برنامهریزی صریح و مستقیم، با تحلیل حجم وسیعی از دادهها، قادر است الگوهای پیچیده و نمایههای سطح بالا را شناسایی کند. شبکههای عصبی عمیق شامل چندین لایه است که هر لایه، ویژگیهای مختلف دادهها را استخراج و پردازش میکند، و فرآیند آموزش آنها بر پایه الگوریتمهای یادگیری نظارتی، بدون نظارت، و نیمهنظارتی انجام میشود.
یادگیری عمیق در مقایسه با یادگیری ماشین سنتی، قابلیتهای بیشتری در استخراج ویژگیهای خودکار و درک عمیقتر از دادهها دارد. این فناوری در حوزههای متنوعی کاربرد دارد، از جمله تشخیص و تفسیر تصویر و ویدئو، ترجمه زبانهای طبیعی، پردازش گفتار، هوش مصنوعی در خودروهای خودران، و سیستمهای پیشنهاددهی.
کاربردهای یادگیری عمیق:
- پزشکی و تشخیص بیماریها: تحلیل تصاویر پزشکی مانند رادیولوژی و MRI برای تشخیص زودهنگام بیماریها
- بینایی ماشین و پردازش تصویر: تشخیص چهره، شناسایی اشیاء، و ویدئوهای امنیتی
- ترجمه زبان و پردازش زبان طبیعی: ترجمه ماشینی، چتباتها و دستیارهای صوتی
- خودروهای خودران و سیستمهای هوشمند حملونقل
- تحلیل دادههای بزرگ و پیشبینیهای اقتصادی و مالی

روشهای آموزش مدلهای یادگیری عمیق
برای آموزش مدلهای یادگیری عمیق، از فرآیندهایی مانند تنظیم معماری شبکه، انتخاب تابع هزینه، و بهکارگیری الگوریتمهای بهینهسازی مانند گرادیان نزولی (Gradient Descent) استفاده میشود. همچنین، بهرهگیری از فناوریهایی مانند GPU و TPU برای سرعتبخشی به آموزش، اهمیت دارد. در ادامه، یک راهنمای قدمبهقدم برای آموزش این مدلها با زبان پایتون آورده شده است.
راهنمای آموزش قدمبهقدم با پایتون:
- نصب کتابخانههای مورد نیاز: TensorFlow، Keras، PyTorch و دیگر ابزارهای مرتبط
- جمعآوری و پیشپردازش دادهها: تصحیح دادهها، نرمالسازی و تقسیم دادهها به مجموعههای آموزش و آزمایش
- ساخت مدل شبکه عصبی: تعریف معماری لایهها، تعداد نورونها، و توابع فعالسازی
- کامپایل کردن مدل: تعیین تابع هزینه، الگوریتم بهینهسازی و معیارهای ارزیابی
- آموزش مدل: اجرای فرآیند آموزش، نظارت بر کاهش خطا و تنظیم پارامترها
- ارزیابی و بهبود مدل: اصلاح معماری، تنظیم هایپراپارامترها و استفاده از تکنیکهایی مانند Dropout و Data Augmentation
- استفاده عملی: تست مدل بر روی دادههای جدید و استنتاج نتایج
تفاوتهای کلیدی بین یادگیری عمیق و یادگیری ماشین عبارتند از:
- ساختار و پیچیدگی مدلها:
- یادگیری ماشین (Machine Learning): شامل الگوریتمهای متنوعی مانند درخت تصمیمگیری، ماشین بردار پشتیبانی، نزدیکترین همسایه و مدلهای خطی که نیاز به طراحی ویژگیهای دستی دارند.
- یادگیری عمیق (Deep Learning): شامل شبکههای عصبی عمیق و چندلایه که قادر به یادگیری ویژگیهای سطح بالا و خودکار هستند، بدون نیاز به استخراج ویژگیهای دستی.
- نیاز به مهارت در مهندسی ویژگیها:
- یادگیری ماشین: نیازمند طراحی و استخراج ویژگیهای مناسب توسط کاربر.
- یادگیری عمیق: قادر است ویژگیها را به طور خودکار از دادههای خام بیاموزد، که کمتر نیازمند مهارت در مهندسی ویژگی است.
- میزان داده مورد نیاز:
- یادگیری ماشین: معمولاً با مجموعه دادههای کوچکتر عملکرد خوبی دارد.
- یادگیری عمیق: نیازمند مجموعههای داده بزرگ و حجیم برای آموزش مؤثر است.
- قدرت مدل و توانایی در تحلیل دادههای پیچیده:
- یادگیری ماشین: در مسائل سادهتر و دادههای کمتر پیچیدهتر کارایی خوبی دارد.
- یادگیری عمیق: بسیار قدرتمند در تحلیل دادههای پیچیده مانند تصویر، صوت و متن است.
- منابع محاسباتی:
- یادگیری ماشین: نیازمند منابع محاسباتی کمتری است.
- یادگیری عمیق: نیازمند منابع محاسباتی قویتر و کارتهای گرافیک (GPU) است برای آموزش سریعتر.
در مجموع، یادگیری عمیق زیرشاخهای از یادگیری ماشین است که با ساختارهای شبکههای عصبی عمیق، قابلیتهای پیشرفتهتری در تحلیل دادههای پیچیده فراهم میکند.
انواع مدلهای یادگیری عمیق در هوش مصنوعی
یادگیری عمیق یکی از شاخههای پیشرفته هوش مصنوعی است که با بهرهگیری از شبکههای عصبی مصنوعی، قادر است الگوهای پیچیده در حجم وسیعی از دادهها را شناسایی و تحلیل کند. آموزش مدلهای یادگیری عمیق فرآیندی است که بدون نیاز به برنامهنویسی صریح، دادهها را میفهمد و تصمیمگیری میکند. در ادامه، به معرفی و توضیح انواع مدلهای مختلف یادگیری عمیق میپردازیم و نقش هر کدام در حل مسائل مختلف توضیح داده میشود.
انواع مدلهای یادگیری عمیق و کاربردهای آنها
این مدلها برای انجام محاسبات پیچیده، تحلیل دادههای بزرگ، و استخراج ویژگیهای مهم در حوزههای مختلف کاربرد دارند. هر مدل بر اساس ساختار و الگوریتم خاص خود، تواناییهای متفاوتی در حل مسائل خاص دارد.
شبکههای کانولوشنی (Convolutional Neural Networks – CNNs): شبکههای کانولوشنی مجموعهای از لایههای عصبی است که برای پردازش دادههای ساختاریافته مانند تصاویر و ویدئوها طراحی شدهاند. این شبکهها با استفاده از فیلترهای کانولوشن، ویژگیهای مهم تصاویر را استخراج میکنند. کاربردهای اصلی شامل پردازش تصاویر پزشکی، شناسایی اشیاء در تصاویر ماهوارهای، تشخیص چهره، و بینایی ماشین است. نحوه کار این شبکهها به گونهای است که با تمرکز بر نواحی خاص، اطلاعات محلی را تحلیل میکنند و در نهایت نتایج دقیقی ارائه میدهند.
خودرمزگذارها (Autoencoders): خودرمزگذارها نوعی شبکه عصبی پیشخور هستند که برای کاهش ابعاد دادهها، حذف نویز، و یادگیری ویژگیهای مهم بدون نظارت طراحی شدهاند. این شبکهها ورودی و خروجی یکسان دارند و در مسائل پیشبینی، تشخیص ناهنجاری، و اکتشاف دارویی کاربرد دارند. به عنوان مثال، در فشردهسازی تصویر و کاهش نویز، از این مدلها بهرهگیری میشود.
حافظه طولانی کوتاهمدت (Long Short-Term Memory – LSTM): شبکههای LSTM برای پردازش دادههای سری زمانی و زمانی که وابستگیهای بلندمدت در دادهها وجود دارد، بسیار مؤثر هستند. این شبکهها شامل چهار لایه به صورت زنجیرهای هستند که میتوانند اطلاعات مهم را در طول زمان نگه دارند و ناهنجاریها و روندها را شناسایی کنند. کاربردهای آن در ترجمه ماشینی، تحلیل بازارهای مالی، پیشبینی آبوهوا، و تشخیص گفتار است.
شبکههای بازگشتی (Recurrent Neural Networks – RNN): شبکههای RNN برای پردازش دادههای پیوسته و متوالی طراحی شدهاند. در این مدلها، خروجی یک مرحله به عنوان ورودی مرحله بعدی استفاده میشود، که امکان تحلیل توالیهای زمانی را فراهم میکند. کاربردهای اصلی شامل بهبود زیرنویس ویدئو، تحلیل متن، ترجمه زبان و سیستمهای گفتگو است.
ماشینهای بولتزمن محدود شده (Restricted Boltzmann Machines – RBM): RBMها شبکههایی با دو لایه هستند که توانایی یادگیری توزیعهای احتمالی روی دادهها را دارند. این مدلها در فازهای اولیه یادگیری، به عنوان ابزارهای پیشپردازش و استخراج ویژگی در سیستمهای پیشنهادگر، توصیهگر و کاهش ابعاد دادهها کاربرد دارند.
شبکههای پرسپترون چندلایه (Multilayer Perceptrons – MLP): MLPها پایهایترین نوع شبکههای عصبی پیشخور هستند که شامل لایههای ورودی، مخفی و خروجی میباشند. این شبکهها در تشخیص گفتار، شناسایی تصویر، ترجمه ماشینی، و کاربردهای دیگر مورد استفاده قرار میگیرند. آنها به دلیل ساختار ساده و قابلیت آموزش سریع، در بسیاری از مسائل پایهای کاربرد دارند.
شبکههای خودسازمانده (Self-Organizing Maps – SOM): این شبکهها در کاهش ابعاد و مصورسازی دادههای بسیار بزرگ کاربرد دارند. SOMها برای تحلیل دادههای پیچیده و غیر خطی طراحی شدهاند و میتوانند دادههای چند بعدی را به فضای دو بعدی نمایش دهند.

نحوه عملکرد یادگیری تقویتی (Reinforcement Learning – RL)
یادگیری تقویتی یکی از شاخههای اصلی و پرکاربرد در حوزه یادگیری ماشین است که بر اساس مفهوم تعامل مستمر و تعاملی میان عامل (Agent) و محیط (Environment) عمل میکند. در این روش، عامل با انجام اقداماتی در محیط، تجربیات و بازخوردهایی (پاداش) دریافت میکند و بر اساس آنها سیاستهایی را برای بهبود عملکرد خود توسعه میدهد. این فرآیند مشابه فرآیند یادگیری انسان و حیوانات است که با آزمون و خطا، بهترین راهحلها را پیدا میکنند.
اجزاء کلیدی یادگیری تقویتی:
- عامل (Agent): سیستم یا موجود زنده که در حال یادگیری است و تصمیم میگیرد چه اقداماتی انجام دهد.
- محیط (Environment): جهان یا فضای مجازی که عامل در آن فعالیت میکند و با آن تعامل دارد. این محیط میتواند واقعی یا شبیهسازی شده باشد.
- پاداش (Reward): سیگنال یا امتیازی که پس از هر اقدام از طرف محیط به عامل داده میشود و نشاندهنده میزان موفقیت یا ناکامی آن اقدام است.
- سیاست (Policy): راهنمایی یا تابعی که تصمیمات عامل را تعیین میکند، یعنی مشخص میکند در هر حالت چه عملی انجام دهد. سیاست ممکن است به صورت قانونهای ثابت یا توابع پیچیده باشد.
- ارزش (Value): معیاری که میزان سودمندی یا پتانسیل آینده یک وضعیت یا اقدام را نشان میدهد و در بهبود سیاستها نقش دارد.
مراحل اصلی فرآیند یادگیری تقویتی:
- تعریف مسئله: تعیین دقیق وضعیتهای ممکن، اقدامات قابل انجام، نحوه دریافت پاداش و هدف نهایی، که پایه و اساس آموزش عامل است.
- انتخاب محیط مناسب: بر اساس نوع مسئله، محیطی طراحی یا انتخاب میشود که بتواند تعاملات مورد نیاز را فراهم کند. این محیط میتواند یک محیط واقعی مانند خودروسازی یا یک شبیهساز مجازی باشد.
- انتخاب الگوریتم مناسب: بسته به پیچیدگی مسئله، الگوریتمهای متنوعی مانند Q-learning، Deep Q-Networks (DQN)، Policy Gradient، Actor-Critic و دیگر تکنیکها مورد استفاده قرار میگیرند.
- آموزش عامل: عامل با انجام اقداماتی در محیط، تجربیات مختلف جمعآوری میکند و بر اساس آنها سیاست خود را بهبود میدهد. این مرحله شامل تکرارهای متعدد و بهروزرسانیهای مکرر است.
- ارزیابی و بهبود عملکرد: عملکرد عامل باید به صورت مداوم ارزیابی شود تا اطمینان حاصل گردد که سیاستها به سمت بهبود حرکت میکنند و در صورت نیاز اصلاحاتی اعمال شود.
نکات مهم:
- یادگیری تقویتی قابلیت حل مسائل پیچیده و استراتژیک را دارد که در آن قوانین مشخص و راهحلهای مستقیم وجود ندارد.
- تکنیکهای اخیر، مانند یادگیری عمیق، باعث توسعه تواناییهای RL در محیطهای بسیار پیچیده و با دادههای زیاد شده است، مثلاً در بازیهای ویدیویی، رباتیک، خودرانها و سیستمهای پیشنهاد دهنده.
- چالشهای رایج در RL شامل مشکلات بهرهبرداری و اکتشاف، مشکل همگرایی، نیاز به دادههای زیاد و زمانبر بودن آموزش است.
- توسعههای جدید در این حوزه شامل یادگیری چند وظیف، یادگیری انتقالی و ترکیب RL با سایر تکنیکهای هوش مصنوعی است که قابلیتهای آن را گستردهتر میسازد.
به طور کلی، یادگیری تقویتی با توانایی بهبود مداوم و سازگاری در محیطهای متغیر، یکی از قدرتمندترین روشها برای حل مسائل پیچیده و تصمیمگیریهای استراتژیک است و در حال حاضر یکی از پیشروترین فناوریها در هوش مصنوعی است.
کاربردهای یادگیری تقویتی (RL)
یادگیری تقویتی (RL) یکی از شاخههای پیشرفته هوش مصنوعی است که در دهههای اخیر توسعه یافته و در طیف وسیعی از حوزهها و صنایع به کار گرفته میشود. این روش بر اساس مفهوم آموزش از طریق تجربه و پاداش، به سیستمها امکان میدهد تا به صورت خودکار و مستقل استراتژیهای بهینه را برای حل مسائل چندوجهی و پیچیده بیاموزند. در ادامه، به مهمترین کاربردهای RL در صنعت و فناوری میپردازیم و نگاهی جامعتر به نقش آن در توسعه فناوریهای نوین خواهیم داشت.
کاربردهای اصلی یادگیری تقویتی:
- بازیهای ویدئویی و هوشمندسازی رقابتی:
در زمینه بازیهای ویدئویی، RL نقش کلیدی در توسعه بازیکنان مصنوعی (Agent) ایفا میکند که توانایی یادگیری استراتژیهای پیچیده و تطبیق با محیطهای دینامیک را دارند. نمونههای برجسته شامل AlphaGo، که توانست بازی Go را از بهترین بازیکنان انسانی برنده شود، و Dota 2، که در آن سیستمهای RL استراتژیهای چندبعدی و تاکتیکهای متنوع را در میدان نبرد یاد گرفتند، است. این فناوریها نه تنها در بازیها، بلکه در آموزش سیستمهای خودران و بهبود تعامل انسان-ماشین نیز کاربرد دارند.

- رباتیک و اتوماسیون صنعتی:
در صنعت رباتیک، RL ابزار قدرتمندی برای آموزش رباتها در انجام وظایف مختلف از جمله ناوبری در محیطهای پیچیده، دستکاری اشیاء، و انجام عملیات دقیق است. به عنوان مثال، رباتهای صنعتی میتوانند به صورت مستقل مهارتهای جدیدی را بیاموزند و در محیطهایی که تغییرات مداوم دارند، عملکرد بهتری داشته باشند. این تکنولوژی در توسعه رباتهای خدماتی، پزشکی و خودرانها نقش مهمی ایفا میکند.
- بهینهسازی سیستمهای مدیریت منابع و زنجیره تأمین:
در حوزه مدیریت منابع، RL به شرکتها کمک میکند تا فرآیندهای توزیع، انبارداری و مدیریت شبکههای ارتباطی را بهینهسازی کنند. این سیستمها با تحلیل دادههای بزرگ، تصمیمگیریهای سریع و دقیق انجام میدهند و باعث کاهش هزینهها، افزایش بهرهوری و پاسخگویی سریعتر به تغییرات بازار میشوند. برای مثال، در سیستمهای حملونقل هوشمند و مدیریت ترافیک، RL میتواند مسیرهای بهینه و زمانبندی مناسب را پیشنهاد دهد.
- خودروهای خودران و حملونقل هوشمند:
در توسعه وسایل نقلیه خودران، RL نقش حیاتی در تصمیمگیریهای لحظهای و بهبود رفتارهای رانندگی در محیطهای مختلف دارد. این الگوریتمها، با تحلیل دادههای حسی و محیطی، تصمیمات هوشمندانهتری در کنترل سرعت، تغییر مسیر و واکنش به موانع اتخاذ میکنند. همچنین، در هواپیماهای بدون سرنشین و سیستمهای حملونقل هوشمند شهری، RL به مدیریت مؤثر ترافیک و کاهش تصادفات کمک میکند.

- بهبود سیستمهای مخابرات و شبکههای ارتباطی در صنعت مخابرات:
RL برای مدیریت تخصیص فرکانس، بهبود کیفیت خدمات، و کاهش تداخلهای سیگنالها به کار میرود. این سیستمها با تحلیل دادههای ترافیک، تنظیمات بهینه را پیشنهاد میدهند که منجر به افزایش سرعت و پایداری شبکه میشود. علاوه بر این، در زمینه اینترنت اشیاء (IoT)، RL میتواند در مدیریت بهینه مصرف انرژی و ترافیک دادهها نقشآفرین باشد.
- الگوریتمها و فناوریهای مرتبط یادگیری تقویتی:
با بهرهگیری از الگوریتمهایی مانند Q-learning، Deep Q-Networks (DQN)، Policy Gradient، و Actor-Critic، توانسته است به عنوان رویکردی قدرتمند در حل مسائل خودکارسازی و بهینهسازی در محیطهای پیچیده شناخته شود. این الگوریتمها با اتکای بر تجربه و پاداش، ماشینها را قادر میسازند تا اقدامات بهترین را در شرایط مختلف انتخاب و اجرا کنند، که در نتیجه منجر به بهبود کارایی، کاهش خطا و افزایش انعطافپذیری سیستمها میشود.
سؤالات متداول:
یادگیری تقویتی (RL) چیست و چگونه کار میکند؟
یادگیری تقویتی نوعی شاخه از هوش مصنوعی است که در آن یک عامل (آنتن) با محیط خود تعامل دارد و با انجام اقداماتی که منجر به دریافت پاداش یا مجازات میشود، سعی در یادگیری بهترین استراتژی برای رسیدن به هدف دارد. در این فرایند، عامل با آزمون و خطا، سیاستهایی را توسعه میدهد که در بلندمدت بیشترین سود را برایش فراهم میکند.
جایگاه یادگیری تقویتی در هوش مصنوعی چیست؟
یادگیری تقویتی یکی از شاخههای مهم و پیشرفته هوش مصنوعی است که در مسائل پیچیده و تصمیمگیریهای استراتژیک کاربرد دارد. این روش در حوزههایی مانند بازیهای کامپیوتری، رباتیک، کنترل سیستمها و بهینهسازی، به دلیل توانایی در یادگیری خودکار و بهبود پیوسته، جایگاه ویژهای دارد و در توسعه هوش مصنوعیهای هوشمند و مستقل نقش کلیدی ایفا میکند.
چه تفاوتهایی بین یادگیری تقویتی و دیگر شاخههای یادگیری ماشین وجود دارد؟
تفاوت اصلی در این است که در یادگیری تقویتی، عامل به صورت فعال در محیط اقدام میکند و بر اساس بازخوردهای آن، استراتژی خود را بهبود میبخشد، در حالی که در یادگیری نظارتی، مدل از دادههای برچسبدار آموزش میبیند و بر پیشبینی یا طبقهبندی تمرکز دارد. همچنین، RL معمولاً در مسائلی که نیاز به تصمیمگیری در زمان واقعی و به صورت پیوسته دارند، بسیار مؤثر است.






