تصور کنید با ماشین خودران به محل کار میروید. هنگام نزدیک شدن به تابلوی ایست، خودرو به جای توقف، سرعت خود را افزایش میدهد و از علامت توقف عبور میکند؛ زیرا سیستم تشخیص علامتهای راهنمایی و رانندگی آن، این علامت را بهعنوان محدودیت سرعت ۶۰ کیلومتر در ساعت تفسیر میکند. در این مطلب از سری مطالب آموزشی وبلاگ پارس وی دی اس به همه چیز درباره يادگيری ماشين خصمانه یا Adversarial میپردازیم.
این در حالی است که سیستم یادگیری ماشین (ML) این خودرو، برای شناسایی علائم توقف آموزش دیده است. اما چطور ممکن است چنین اشتباهی رخ دهد؟
احتمالاً فردی برچسبهایی روی علامت توقف قرار داده است تا سیستم را فریب دهد و تصور کند که علامت، محدودیت سرعت است. این اقدام ساده، نمونهای از حمله خصمانه به سیستمهای یادگیری ماشین و هوش مصنوعی (Adversarial Machine Learning) است. این نوع حملات، تهدیدهای جدی برای امنیت و کارایی سیستمهای مبتنی بر هوش مصنوعی محسوب میشوند و در حال حاضر یکی از حوزههای مهم تحقیق در علوم کامپیوتر و امنیت سایبری هستند.

در ادامه، قصد داریم با مروری بر مفهوم یادگیری ماشین خصمانه و نحوه مقابله با آن، به درک عمیقتری از چالشهای این حوزه برسیم.
یادگیری ماشین خصمانه چیست؟
یادگیری ماشین خصمانه یا هوش مصنوعی متخاصم (Adversarial AI)، شاخهای از تحقیقات در زمینه هوش مصنوعی است که بر بررسی و توسعه روشهایی تمرکز دارد که میتوانند مدلهای هوشمند را در برابر حملات و ترفندهای فریبنده آسیبپذیر کنند. این حملات معمولاً با هدف گمراهسازی سیستمهای هوشمند انجام میشوند و میتوانند در مراحل مختلف توسعه و پیادهسازی مدلها رخ دهند، از جمله:
- دستکاری دادههای آموزشی: با افزودن دادههای نادرست یا سوگیریهای خاص، مدل را به سمت نتایج نادرست سوق دهند.
- مسمومسازی مدل: با تغییرات در پارامترهای داخلی مدل، کارایی آن را کاهش دهند.
- ورودیهای فریبنده (Adversarial Inputs): ورودیهایی طراحی شده که سیستم را فریب میدهند و منجر به خروجیهای نادرست میشوند.
این حملات میتوانند پیامدهای خطرناکی در کاربردهای حیاتی مانند خودروهای خودران، تشخیص پزشکی، سیستمهای امنیتی و تشخیص چهره داشته باشند. به عنوان مثال، مهاجمان میتوانند از این تکنیکها برای دستکاری سیستمهای تشخیص هویت، فریبدادن سیستمهای امنیتی، یا حتی کنترل وسایل نقلیه هوشمند بهرهبرداری کنند.
مثالهای عملی از حملات خصمانه:
- حمله به مدلهای تشخیص تصویر:
یکی از شناختهشدهترین نمونههای حملات خصمانه، حمله به شبکههای عصبی است که برای تشخیص تصاویر به کار میروند. فرض کنید تصویری از یک پاندا به درستی توسط مدل تشخیص داده شده است. مهاجم با افزودن نویز بسیار جزئی و نامرئی (Adversarial Noise) به تصویر، میتواند سیستم را فریب دهد. در نتیجه، مدل تصویر دستکاریشده را بهعنوان یک حیوان متفاوت، مثلاً پاندا، شناسایی میکند، هرچند که تغییرات قابل مشاهده برای انسان ناچیز است.
این نمونه نشان میدهد که حتی کوچکترین تغییرات میتوانند منجر به خطاهای بزرگ در سیستمهای هوشمند شوند.

- حملات به خودروهای خودران
در حوزه خودروهای خودران، حملات خصمانه میتواند با دستکاری کوچک در علائم راهنمایی و رانندگی، سیستم تشخیص آنها را فریب دهد. برای مثال، تغییرات جزئی در شکل، رنگ یا برچسبهای یک علامت توقف میتواند منجر به این شود که خودرو، علامت را بهعنوان محدودیت سرعت تفسیر کند یا اصلاً آن را نبیند. چنین حملاتی، امنیت سفرهای خودران را به خطر میاندازند و ممکن است منجر به تصادفهای جدی شوند.
اهمیت مقابله با حملات خصمانه هوش مصنوعی:
با توجه به آسیبپذیریهای موجود، پژوهشهای بسیاری در حوزه توسعه راهکارهای مقابله با حملات خصمانه انجام شده است. این اقدامات شامل روشهایی برای:
- بهبود مقاومتی مدلها: طراحی معماریهایی که در برابر ورودیهای فریبدهنده مقاومتر باشند.
- شناسایی و فیلتر ورودیهای مخرب: توسعه سیستمهایی برای تشخیص و حذف دادههای فریبدهنده قبل از وارد شدن به مدل.
- آموزش مدلها با دادههای مقاوم: استفاده از تکنیکهایی مانند آموزش مقاوم در برابر حملات (Adversarial Training) برای کاهش آسیبپذیری.
حملات هوش مصنوعی متخاصم چگونه عمل میکنند و چه تاثیری بر سیستمهای هوشمند دارند؟
حملات هوش مصنوعی متخاصم (Adversarial AI Attacks) فرآیندهایی هستند که با بهرهگیری از آسیبپذیریها و محدودیتهای ذاتی در مدلهای یادگیری ماشین، بهویژه شبکههای عصبی عمیق (Deep Neural Networks – DNN)، سعی در فریب سیستمهای هوشمند دارند. این حملات با دستکاری دادههای ورودی یا خود ساختار مدل، هدفشان تولید نتایج نادرست، خطاهای تصمیمگیری یا رفتارهای غیرقابل پیشبینی است. در واقع، مهاجمان از این حملات برای سوءاستفاده از نقاط ضعف در سیستمهای AI و ML بهره میبرند تا تاثیرات مخرب و ناخواستهای ایجاد کنند.
حملات خصمانه معمولاً از یک الگوی چهار مرحلهای پیروی میکنند که شامل موارد زیر است:
- شناخت سیستم هدف
- طراحی نمونههای متخاصم
- بهرهبرداری و اجرای حمله
- ارزیابی و تحلیل نتایج

مرحله ۱: شناخت سیستم هدف در این مرحله، مهاجمان سایبری باید درک دقیقی از چگونگی عملکرد سیستم هوشمند مورد نظر پیدا کنند. آنها با تحلیل الگوریتمهای مورد استفاده، روشهای پردازش داده، ساختار مدل و الگوهای تصمیمگیری، سعی در کشف نقاط ضعف میکنند.
برای این منظور، از تکنیکهایی مانند مهندسی معکوس، تحلیل کد و بررسی مدلهای آموزشدیده استفاده مینمایند. شناخت دقیق سیستم، به آنها کمک میکند تا بهترین راهکارهای حمله، مانند طراحی نمونههای متخاصم، را تدوین کنند.
مرحله ۲: ایجاد ورودیهای مخالف (نمونههای متخاصم) پس از درک سیستم، مهاجمان قادر خواهند بود نمونههای ورودی متخاصم را طراحی کنند. این نمونهها با تغییرات کوچک در دادههای ورودی، هدف دارند سیستم را فریب دهند. مثلاً، در تشخیص تصویر، تغییرات جزئی در پیکسلها میتواند منجر به تغییر طبقهبندی شود، در حالی که انسان متوجه تفاوت نمیشود.
در پردازش زبان طبیعی (NLP)، تغییرات در کلمات یا عبارات ممکن است باعث طبقهبندی نادرست متن شود. تکنیکهایی مانند حملات بر پایه گرادینت (Gradient-based Attacks)، نمونهسازی تصادفی یا تکنیکهای بهبود داده برای تولید این نمونهها استفاده میشود.
مرحله ۳: بهرهبرداری و اجرای حمله در این مرحله، مهاجمان نمونههای متخاصم ساختهشده را وارد سیستم میکنند یا در فرآیندهای واقعی به کار میگیرند. هدف، ایجاد رفتار نادرست یا ناخواسته در سیستم است؛ مانند فریب در سیستمهای تشخیص چهره، ترسیم مسیر نادرست در وسایل نقلیه خودران، یا دور زدن سیستمهای امنیتی و احراز هویت.
این حملات میتوانند منجر به تصمیمگیریهای اشتباه، کاهش دقت سیستم یا آسیبپذیریهای امنیتی شوند. همچنین، مهاجمان ممکن است از این روشها برای دستکاری نتایج یا کسب دسترسیهای غیرمجاز بهرهبرداری کنند.
مرحله ۴: اقدامات پس از حمله و ارزیابی نتایج حملات خصمانه میتواند جدی و حتی تهدیدکننده باشد، بهویژه در حوزههایی مانند سلامت، حملونقل و امنیت ملی. به عنوان مثال، اشتباه در تشخیص بیماریها، تصادفات خودروهای خودران یا نفوذ به سامانههای حساس میتواند عواقب جبرانناپذیری داشته باشد. بنابراین، توسعه راهکارهای مقابله و دفاع در برابر این حملات اهمیت ویژهای دارد.
این راهکارها شامل موارد زیر است:
- طراحی معماریهای مدل مقاومتر و ایمنتر
- آموزش مدلها با نمونههای متخاصم (آموزش متخاصم)
- استفاده از تکنیکهای تشخیص نمونههای متخاصم و فیلتر آنها
- بهکارگیری روشهای پیشبینی و اعتبارسنجی مداوم سیستمها در برابر حملات
- توسعه الگوریتمهای مقاوم در برابر تغییرات کوچک در دادهها
علاوه بر این، تحقیقات جاری بر روی توسعه تکنیکهای جدید مانند یادگیری مقاوم (Robust Learning)، یادگیری بدون نیاز به برچسب (Semi-supervised Learning) و استفاده از مدلهای توزیعشده برای کاهش آسیبپذیریها متمرکز است.
انواع حملات خصمانه در حوزه هوش مصنوعی و یادگیری ماشین:
حملات خصمانه یا حملات adversarial، تهدیدهای جدی برای امنیت و صحت سیستمهای هوش مصنوعی محسوب میشوند. این حملات به روشهای مختلفی صورت میگیرند و بر اساس نوع هدف، سطح دانش مهاجم و نحوه اجرای آنها تقسیمبندی میشوند.
که شامل:
تقسیمبندی بر اساس سطح دانش مهاجم:
حملات جعبه سفید (White Box Attacks): در این نوع حمله، مهاجم دانش کامل و دقیقی از معماری، وزنها و جزئیات داخلی مدل هوش مصنوعی دارد. این اطلاعات به او امکان میدهد تا حملات بسیار هدفمند و مؤثر طراحی کند. چنین حملاتی معمولاً پیچیدهتر و دقیقتر هستند چون مهاجم میتواند از اطلاعات داخلی برای اجرای حمله بهرهمند شود.
حملات جعبه سیاه (Black Box Attacks): در این حالت، مهاجم تنها به خروجیها یا نتایج مدل دسترسی دارد، ولی از ساختار درونی آن اطلاعی ندارد. این نوع حمله نیازمند روشهای تخمین یا شبیهسازی مدل است و معمولاً سختتر و زمانبر است، اما در عین حال میتواند با موفقیت انجام شود.
انواع حملات خصمانه بر اساس نحوه اجرا و عملکرد:
الف) حملات فرار (Evasion Attacks): حملات فرار زمانی رخ میدهند که مهاجم با تغییرات نامحسوسی در دادههای ورودی، سیستم هوش مصنوعی را فریب میدهد. هدف این است که ورودی دستکاری شده، سیستم را به اشتباه بیندازد بدون اینکه تغییرات قابل تشخیص باشد. این نوع حملات در مواردی مانند تشخیص تصویر، سیستمهای امنیتی، و رانندگی خودران بسیار خطرناک است.
- حملات غیرهدفمند (Untargeted Attacks): هدف این است که مدل، نتیجه نادرستی تولید کند، بدون توجه به نوع خاص نتیجه. مثلاً، تغییر یک علامت توقف به گونهای که سیستم آن را شناخته نشود.
- حملات هدفمند (Targeted Attacks): مهاجم قصد دارد مدل را فریب دهد تا نتیجه خاص و نادرستی بدهد، مثلاً طبقهبندی اشتباه یک تومور خوشخیم به عنوان بدخیم، که میتواند منجر به تصمیمگیریهای پزشکی نادرست شود. مقابله با حملات فرار نیازمند تکنیکهای پیشرفتهای مانند آموزش مقاوم، استفاده از تکنیکهای تئوریک و روشهای تشخیص حملات است، چرا که مهاجمان ممکن است از تکنیکهای بهینهسازی برای نفوذ استفاده کنند که تشخیص آنها دشوار است.
ب) حملات مسمومیت (Poisoning Attacks): در این نوع حمله، مهاجم دادههای آموزشی را دستکاری میکند تا مدل آموزشدیده، نتایج نادرستی ارائه دهد یا رفتارهای موردنظر او را نشان دهد. این حملات میتواند به صورت تزریق دادههای آلوده در فرآیند جمعآوری دادهها، یا تغییر در نمونههای آموزشی انجام شود.
به عنوان مثال، افزودن نمونههای مخرب به دادههای آموزش ترجیحاً در زمانی که مدل در حال آموزش است، میتواند منجر به کاهش کارایی یا آسیبپذیری مدل شود. این نوع حملات، بهویژه در سیستمهایی که بر دادههای جمعآوریشده از منابع مختلف تکیه دارند، بسیار خطرناک است و نیازمند روشهای مقابلهای مانند اعتبارسنجی دادهها، فیلترهای پیشپردازش و آموزش مقاوم است.
ج) حملات انتقالی (Transfer Attacks): حملات انتقالی یکی از چالشهای مهم در حوزه حملات خصمانه است. در این نوع حمله، مهاجم یک مدل خصمانه (مدل متخاصم) را طراحی میکند که بر روی یک سیستم هدف، بدون نیاز به دسترسی مستقیم، تأثیرگذار است. این حمله بر پایه این فرض استوار است که مدلهای مختلف، به خصوص در شبکههای عمیق، الگوهای مشابهای را یاد میگیرند، بنابراین حملهای که روی یک مدل طراحی شده، میتواند بر روی مدلهای دیگر نیز مؤثر باشد.
این تکنیک، نشاندهنده قابلیت انتقال حملات است و نشان میدهد که مهاجمان میتوانند با ساختن نمونههای خصمانه بر اساس یک مدل، آنها را بر روی چندین سیستم مشابه تست و به کار ببرند. مقابله با حملات انتقالی، نیازمند توسعه روشهایی برای آموزش مدلهای مقاوم در برابر نمونههای خصمانه و استفاده از تکنیکهای دفاعی مبتنی بر تنوع و تنشزدایی است.
راهکارهای مقابله و دفاع در برابر حملات خصمانه:
آموزش مقاوم (Adversarial Training): آموزش مدلها با نمونههای خصمانه برای افزایش مقاومت آنها.
- تشخیص حملات (Adversarial Detection): توسعه سیستمهایی برای شناسایی نمونههای دستکاری شده.
- تنوع در معماری و دادهها: استفاده از مدلها و دادههای متنوع برای کاهش اثرپذیری.
- طراحی مدلهای مقاوم و تئوریک: بر اساس نظریههای یادگیری مقاوم و بهبود معماریها.
- بهروزرسانی مداوم و نظارت مداوم بر مدلها برای شناسایی رفتارهای نادرست یا حملات جدید.
در نتیجه، شناخت انواع حملات خصمانه و توسعه راهکارهای مقابله کارآمد، نقش مهمی در تضمین امنیت و صحت سیستمهای هوش مصنوعی دارد. تحقیقات و توسعههای مستمر در این حوزه، کلید جلوگیری از نفوذ مهاجمان و حفظ اعتماد در سیستمهای مبتنی بر هوش مصنوعی است.
نحوه دفاع در برابر حملات هوش مصنوعی و یادگیری ماشین خصمانه:
در دنیای امروز، تهدیدات مرتبط با هوش مصنوعی و یادگیری ماشینهای خصمانه (Adversarial) به یکی از مهمترین چالشهای امنیت سایبری تبدیل شده است. ماهیت پیچیده و چندوجهی این تهدیدات نیازمند استراتژیهای چندلایه، فعال و جامع است که راهحلهای فنی، سازمانی و آموزشی را ترکیب میکند.
هدف اصلی، ساختن یک چارچوب مقاوم، انعطافپذیر و پیشگیرانه است که نه تنها قادر به شناسایی و جلوگیری از حملات است، بلکه بتواند در صورت وقوع، پاسخ سریع و موثری ارائه دهد.
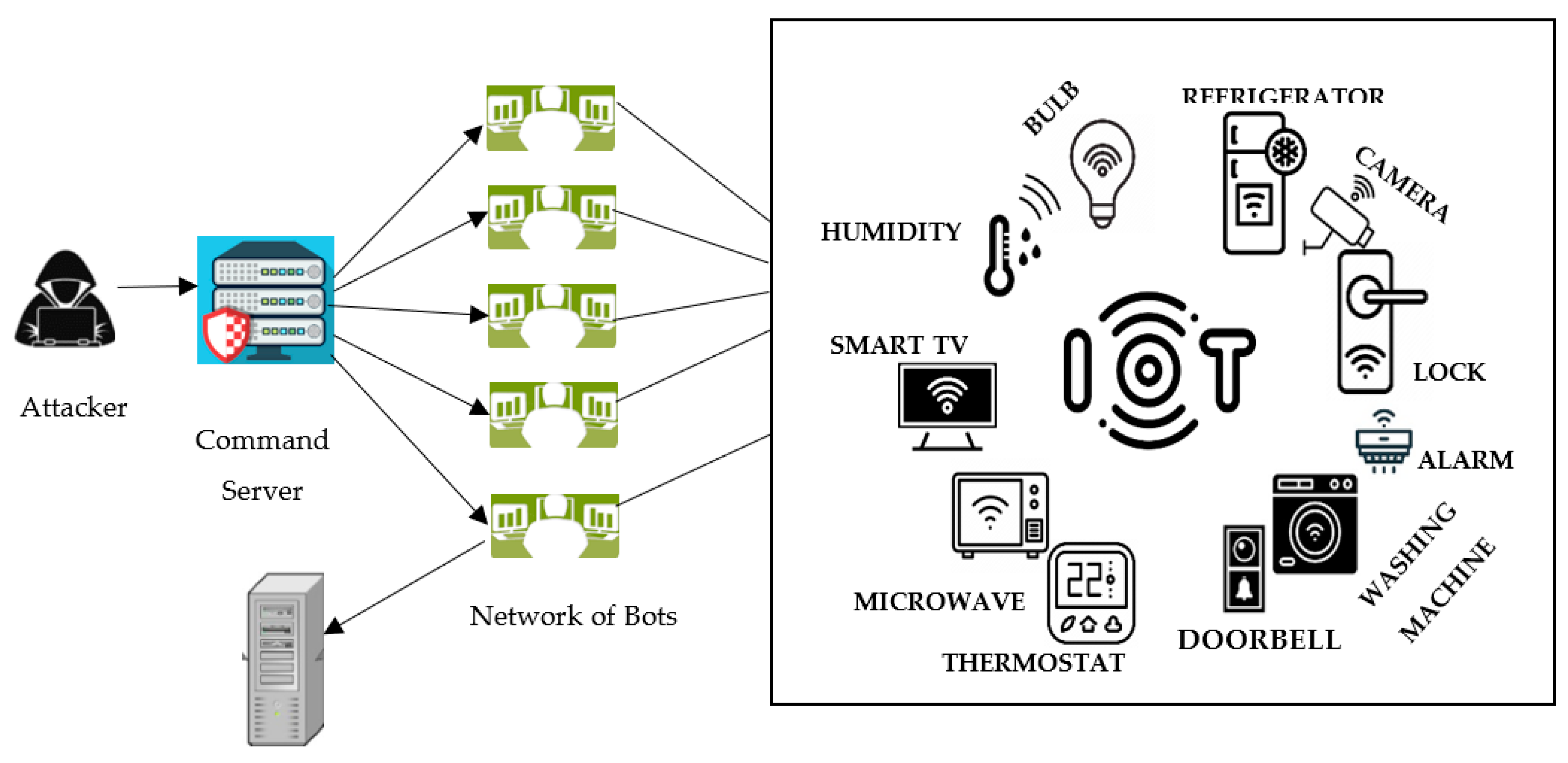
پیشگیری و تشخیص اولیه گام نخست در مقابله با حملات خصمانه، تمرکز بر پیشگیری و تشخیص زودهنگام است. این شامل اجرای سیستمهای امنیتی پیشرفته مبتنی بر هوش مصنوعی است که ورودیهای متخاصم را قبل از اثرگذاری شناسایی و خنثی میکنند.
تکنیکهای مهم در این حوزه عبارتند از:
- مدلهای یادگیری ماشین مقاوم: این مدلها نسبت به دستکاریهای دشمنان حساسیت کمتری دارند و توانایی تشخیص نمونههای مخرب را دارند.
- سیستمهای تشخیص ناهنجاری (Anomaly Detection): این سیستمها میتوانند الگوها یا ورودیهای غیرمعمول و مشکوک را شناسایی کنند، که نشاندهنده حملات احتمالی است.
- فیلترهای پیشپردازش و اعتبارسنجی ورودیها: برای کاهش احتمال نفوذ دادههای مخرب به سیستم، از تکنیکهای اعتبارسنجی و تصفیه دادهها استفاده میشود.
آموزش مدل هوش مصنوعی خصمانه یکی از مؤثرترین روشها در مقابله با حملات، آموزش تیمها و توسعهدهندگان است. آموزش خصمانه (Adversarial Training) روشی است که در آن مدلها در مقابل نمونههای مخرب آموزش میبینند تا در برابر حملات مقاومتر شوند.
این فرآیند شامل:
- تقویت مجموعه دادههای آموزشی با نمونههای متخاصم.
- آموزش مدلها در مواجهه با حملات فرضی و واقعی.
- آموزش تیمهای امنیتی برای شناسایی نشانههای حملات و پاسخ سریع. با این رویکرد، مدلها توانایی تشخیص ورودیهای مخرب و برچسبگذاری آنها به عنوان تهدید را پیدا میکنند، که به افزایش امنیت کلی سیستم کمک میکند.
تقطیر دفاعی (Defensive Distillation):
تقطیر دفاعی یکی از تکنیکهای پیشرفته در مقاومسازی مدلهای یادگیری ماشین است. این روش شامل آموزش یک مدل اصلی (Teacher Model) و سپس استفاده از خروجیهای نرم (Soft Labels) آن برای آموزش یک مدل جدیدتر و فشردهتر (Student Model) است. این کار باعث میشود که مدل نهایی حساسیت کمتری نسبت به تغییرات کوچک و نویزهای موجود در حملات خصمانه نشان دهد. نتیجه نهایی، مدلی است که در برابر حملات متخاصم مقاومتر است و توانایی تشخیص و پاسخ مناسب دارد.
نظارت مستمر و پایش سیستمها:
پایش و کنترل مداوم سیستمهای هوش مصنوعی، نقش حیاتی در شناسایی حملات و رفتارهای غیرمنتظره دارد. ابزارهای نظارتی باید توانایی تشخیص رفتارهای غیرعادی و تحلیل الگوهای خروجی را داشته باشند. علاوه بر این، اجرای پروتکلهای امنیتی مانند رمزگذاری اطلاعات، کنترل دسترسی و مدیریت کلیدها، از اقدامات ضروری برای جلوگیری از دستکاری و دسترسی غیرمجاز است. این اقدامات کمک میکنند تا سیستم در برابر حملات پیچیده و مداوم مقاوم باقی بماند.
آموزش مداوم و ارتقاء سطح آگاهی ارتقاء سطح دانش و مهارت تیمهای عملیاتی و توسعهدهندگان، یکی از ارکان مهم استراتژی دفاعی است. برنامههای آموزشی باید شامل موارد زیر باشد:
- شناخت ماهیت حملات خصمانه و تکنیکهای شناسایی آنها.
- آگاهی از آسیبپذیریهای رایج در مدلهای هوش مصنوعی.
- آموزش بهروزرسانی و اصلاح مداوم مدلها بر اساس تهدیدهای جدید.
- تمرینهای شبیهسازی و سناریوهای حمله برای افزایش آمادگی تیمها. این آموزشهای تخصصی، سازمان را در برابر نفوذهای پیچیده و حملات جدید مقاومتر میسازد و از کاهش آسیبپذیریهای سازمانی جلوگیری میکند.
ارزیابی آسیبپذیری و تست نفوذ:
ارزیابی منظم آسیبپذیریهای سیستمهای هوش مصنوعی، کلید شناسایی نقاط ضعف و تقویت دفاعها است.
فرآیندهای ارزیابی شامل:
- تست نفوذ (Penetration Testing): شبیهسازی حملات خصمانه برای آزمایش مقاومت سیستم.
- ارزیابیهای مبتنی بر سناریو: تحلیل نحوه واکنش سیستم در مواجهه با حملات فرضی.
- تحلیل استحکام مدل و امنیت دادهها: بررسی حساسیت مدلها و محافظت از دادهها در برابر دستکاری. این ارزیابیها به تیمهای امنیتی کمک میکنند تا استراتژیهای امنیتی خود را اصلاح و بهروز کنند و سیستمهای مقاومتر در برابر حملات آینده بسازند.
جمع بندی:
فناوریهای نوین مانند استفاده از بلاکچین برای تضمین صحت دادهها، هوش مصنوعی توضیحپذیر (Explainable AI) برای درک بهتر تصمیمات مدل و امنیت سایبری مبتنی بر هوش مصنوعی، نقش مهمی در حفاظت از سیستمهای هوشمند دارند. همچنین، توسعه الگوریتمهای مقاوم در برابر حملات، استفاده از یادگیری ماشین خودسازمانده و سیستمهای مبتنی بر یادگیری بدون نظارت (Unsupervised Learning) میتواند به بهبود امنیت و پایداری سیستمهای هوش مصنوعی کمک کند.
با توجه به رشد سریع و پیچیدگی روزافزون تهدیدهای خصمانه در حوزه هوش مصنوعی، توسعهدهندگان و سازمانها باید همواره در حال بهروزرسانی دانش، فناوریها و استراتژیهای دفاعی خود باشند. شناخت کامل ماهیت حملات، پیادهسازی راهکارهای چندلایه و آموزش مداوم تیمها، کلید مقابله مؤثر با این چالشها است و تضمینکننده امنیت و پایداری سیستمهای هوشمند در فضای دیجیتال است.






